
Nemo from NVIDIA, Ownable AI Muscle, If You Can Lift It
By BT | Business Orchestrator | Builder of AI-First Businesses
"Open weights mean nothing if you don't have the muscles to lift them."
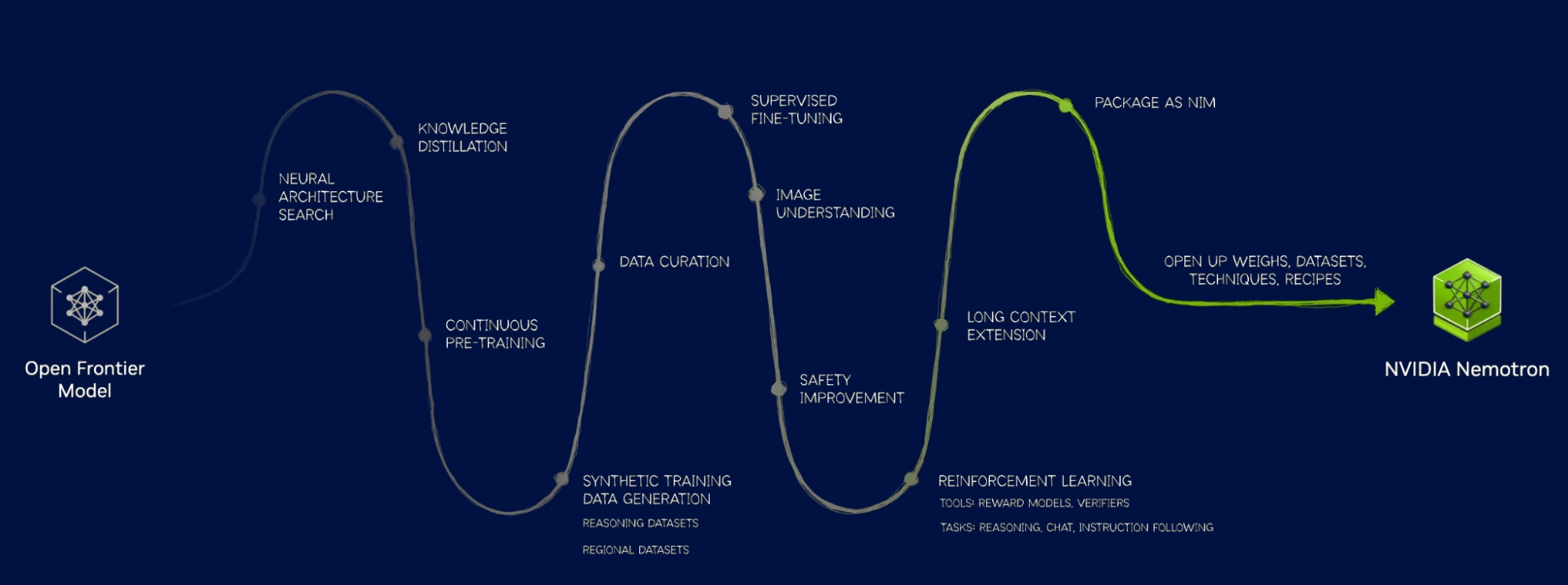
So NVIDIA just handed us Nemotron, a family of enterprise-grade, openly licensed large language models (LLMs) with the performance to rival GPT‑4 and the freedom to actually own your stack.
Sounds like a dream, right? It is, but only if you've got the infrastructure to carry it.
Let me break it down in BT style: this isn't plug-and-play. This is enterprise-grade AI horsepower, and it demands an equally serious pit crew.
What is Nemotron?
Nemotron is NVIDIA's family of LLMs designed for reasoning, instruction-following, code, math, and deep domain use cases, available in 15B, 34B, 70B, and even 340B parameter variants.
And here's the best part? It's open-weight + commercially usable, integrated with:
NeMo Framework
For fine-tuning and evaluation
NIM Containers
For deployment as microservices
GPU Optimized
For H100 and A100 GPUs, running in FP8/BF16
But Here's the Catch: Infrastructure Is the Barrier to Entry
Let's not romanticize it. Here's what it really takes to deploy or fine-tune these models:
GPU Muscle
Nemotron‑4 15B: Needs ~40GB VRAM just for inference.
Nemotron‑4 340B: You'll need 8+ A100 or H100 GPUs, with fast interconnect.
Cloud GPU costs: $5–$8/hour per GPU.
On-prem: $30K–$100K per node.
Welcome to the big leagues.
Storage & Data Throughput
Training sets run into 8–9 trillion tokens. You'll need terabytes of high-speed NVMe, and bandwidth to match.
DevOps Complexity
Model serving, token streaming, scaling, logging, not for solo tinkerers.
Use NVIDIA NIM containers and NeMo Agent Framework if you want sane deployment.
NVIDIA NeMo + NIM Deployment DocsSo What's the BT Strategy for Founders & MSMEs?
Don't go brute force. Go smart orchestration:
Use LoRA or QLoRA fine-tuning
Start with 15B or 7B OpenReasoning variants
Deploy as AI Agents using NeMo + NIM + RAG pipelines
Partner with infra providers (e.g., CoreWeave, G42, Lambda Labs)
Prioritize data privacy and ownership over shiny SaaS wrappers
You don't need to be a GPU billionaire, you need to be smart about stack design.
What We're Doing at BETTROI
We're embedding Nemotron-based AI agents into our AgentX ecosystem, copilots that live inside your org, trained on your data, and never exposed to third-party APIs.
Your Sales Bot
Your Ops Copilot
Your Compliance Concierge
All powered by Nemotron. All hosted with privacy-first orchestration. No API ping-pong. No lock-in.
Final Word
Nemotron is not for tourists. It's for builders who are serious about owning their AI narrative, with eyes open, wallets ready, and a vision bigger than just ChatGPT wrappers.
So here's my challenge to you: Are you renting AI hype? Or are you ready to own AI muscle?